Chomsky Pushdown
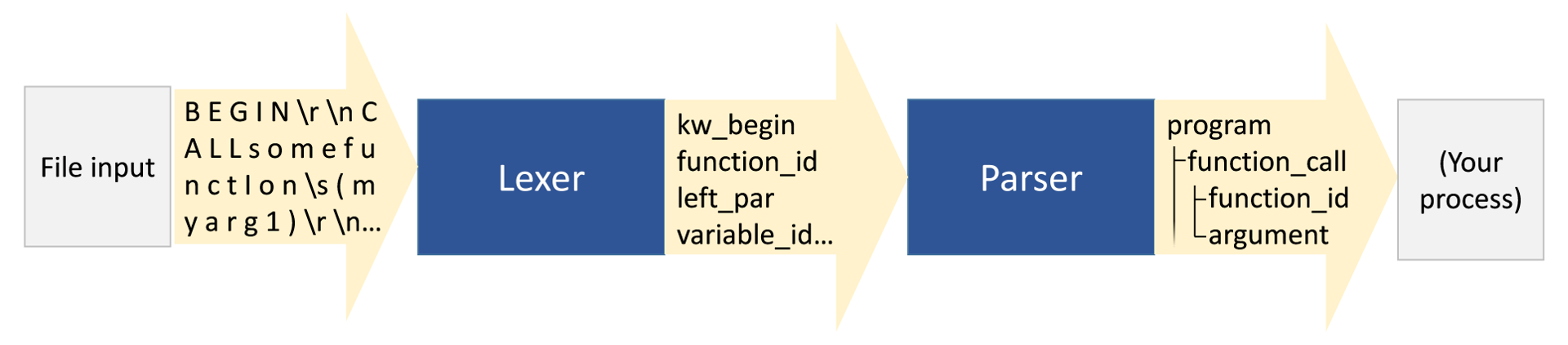
Published in Computing There is an ideal among programming language designers that a language should be readily expressed using a declarative notation such has Extended Backus-Naur Form. This form offers many advantages for language developments, as the declarative syntax is easily digested and supported by a variety of toolkits in varying forms. A good example of such a tool kit is SableCC which offers a powerful processing pipeline using a language very heavily based on EBNF and is capable of generating LALR(1) parsers for most context free grammars, or Bison, another popular parser generator tool kit. An important feature of these tools is that they employ a parsing pipeline with distinct stages for lexing and parsing. This allows the generated automata to be much smaller, as each stage of the pipeline has a relatively simple problem to solve: the lexer is responsible only for breaking the text into tokens, while the parser must only create the abstract syntax tree from a limited set of symbols rather than every possible combination of letters in the alphabet. As such two relatively simple finite state automata can work in tandem to produce a powerful parsing pipeline, where either a horrendously complicated automata, or hand-coded parser would be required in order to do the processing in one step. This pipeline divides the parsing problem into two distinct steps, lexing and parsing each handled by their own Deterministic Finite-state Automaton (DFA).
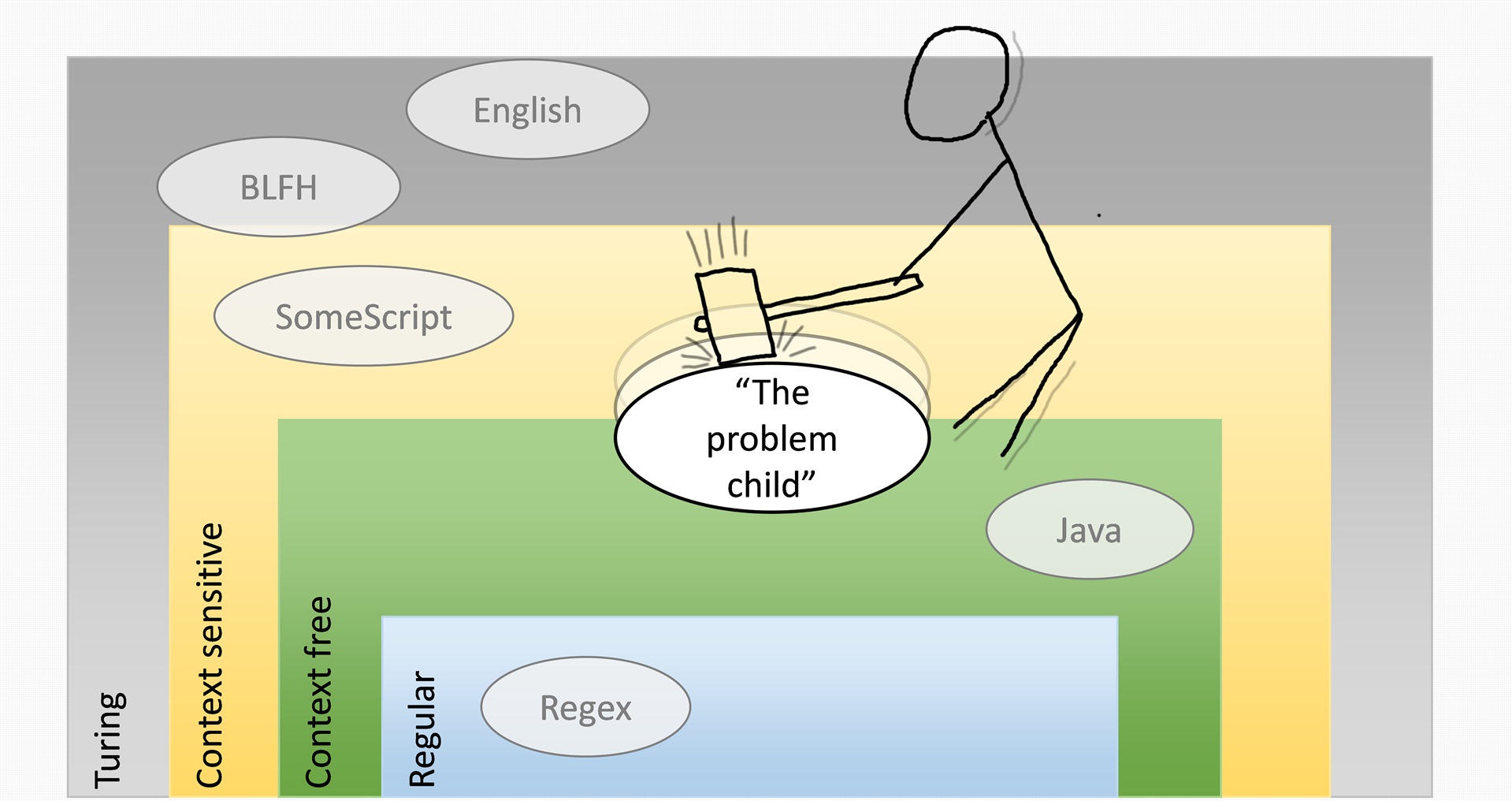
Lexing is concerned with the tokenisation of the input text stream (or array of characters) into a stream of tokens, such as FUNCTION, myVariableName or "my string". Parsing then uses these tokens as its atomic units to construct the abstract syntax tree. Both the lexing DFA (lexer) and parsing DFA (parser) must be able to produce a unique result for their given input stream which consumes the entire input, and also has no valid alternative. While this arrangement works extremely well for context-free languages, where a grammar is even the slightest bit context sensitive it introduces ambiguities that prevent a single canonical parse tree being generated a.k.a. a parse table conflict or lexical conflict. But what if a language is not heavily contextual? What if there are only a few features in the language that prevent it from being truly context-free? Can such a language still benefit from the fast and efficient parsing that is offered by these tools? There are some techniques that make it is possible for at least some of these languages to have this lexing-parsing pipeline applied. The Chomsky hierarchy defines four types of language, each being progressively more constrained: For practical purposes, the distinction between a Turing language and a context-sensitive language is limited, as both require procedural code to process input. The more important distinction comes between the first two types, and the latter two: context-free languages and regular languages can be described using declarative syntax, and be readily processed using automata built to a predetermined pattern.
This is why it is important when a particular language can be coerced into being context-free, when it is not quite context-free to start with. The case in point for me is a language derived from Basic that was originally designed to be used in an interpreter, and is traditionally backed by a monolithic Turing parser. This language has a few features that make straightforward parsing difficult.
First a form of contextual structure definition and inclusion that looks completely identical in some scenarios and thus can only be reliably distinguished by already knowing whether the structure has been declared. The second is a peculiar form of text literal declaration that would be more familiar in a polyglot language such as HTML, where a combination of words that individually have different meanings elsewhere in the syntax are used to distinguish the start and end of the text block. The image structure in this language could be viewed as a form of singleton struct in C#. Being a singleton, it may only be declared once within the program, and can subsequently be used repeatedly by making reference to the image. Declaration must always precede usage, as the language uses a single-pass compiler.
Code can look like this (keywords capitalised for ease of understanding): The obvious issue with this syntax is that an image opening followed by a variable declaration may be either specifying part of an image or a usage of a defined followed by a subroutine variable. Without unbound look ahead, it is impossible for a context free parser to tell between the two scenarios; there may be any number of declarations between the image opening and a statement that would clarify the ambiguity, hence this structure yields a parse-table conflict.
This behaviour can be emulated by a flexible rules based pre-processor, which can perform some stateful tasks before handing the text onto the parser. In this case a rule modifies the first occurrence of an image declaration to use a new keyword 'IMAGED' in place of 'IMAGE', creating a context-free syntax that distinguishes between image declaration and image usage. Another challenging element of the language for a typical dual-DFA pipeline is the presence of string literals that are delimited by a combination of keywords, such as the example below: In a monolithic context-free parser that combines lexing and parsing it may be possible to define a context-free grammar that successfully handles this case, but for a dual-DFA pipeline this is not possible without assistance.
The particular challenge is that the lexer must be able to map the same sequence of characters to the same token regardless of context. Normally this is achieved by adding a string delimiting character (such as quote marks) at the start and end of a literal, which is not reused for other purposes elsewhere in the grammar. In our case, both the “TEXT" and “END" keywords have legitimate uses elsewhere in the grammar for other purposes, thus cannot be dedicated string delimiting markers.
An alternative approach might be to treat the string literal as an abstract syntax tree construct, and have the parser build a structure representing the string. This does not work either, due to the string's unpredictable content.
The solution to this particular problem is to make use of a regular expression to add explicit delimiters that are unique symbols, thus allowing the lexer to readily identify the text as a string literal.
A convenience of the language in question is that it makes use only of EBCDIC characters, roughly equivalent to lower ASCII. With the parser running in a modern UTF-16 compatible environment, this leaves thousands of characters that our system can process with no expectation that they would be valid in the original text. I chose upper-ASCII characters « and » as alternative string delimiters to insert.
The text after transformation is like this: Having added delimiters to these special literals, a further problem needs to be solved: Value substitution. Like many server-side template based web page formats, the values can be substituted into the literal text, by using curly-brace expressions (e.g. {myValue} ). As the curly-brace expressions do have proper delimiters and contents that form valid expressions, these can be accommodated in the lexer by providing four classes of special string literal as below: By classifying the special literals this way, is means that the stream of tokens being passed to the parser is easy to work with. For the example above it becomes:
kw_text, kw_to, identifier, newline, specialtext_lit, identifier, specialtext_lit, kw_end, kw_text In another feature that seems to have arrived through organic language development over years, there are multiple valid syntaxes for calling functions, the applicability of which is sometimes decided only after parsing the function name. Once again, the particular variance between calling conventions is unfriendly to both the parser and the lexer.
In classic BASIC fashion, this language supports multiple PRINT statements: PRINT, PRINTTEXT and AUDITTEXT. From a data path analysis point of view, these are just another function that sinks information out of the application. The language however just sees these as another type of statement, which accepts a very liberal argument list. PRINTTEXT and AUDITEXT in particular are awkward, echoing the problem above with plaintext literals appearing in a statement without explicit delimiters.
The solution to this was to create keyword tokens specifically for these functions, and treat them not as regular function calls but as entirely different entities for the purpose of parsing. The easiest way to practically implement the solution was to bolt a stateful pre-processor into the front of lexing-parsing pipeline, giving sanitised text to the DFAs generated by my favoured parser generator, SableCC. This pre-processor is called FlexPP, and I will write about that soon.The Dual-DFA LALR pipeline
The problem
The Chomsky hierarchy
Case in point
Contextual structure definition
'Image declaration
IMAGE Foo
'Image member declaration
Abc IS FLOAT
Def IS STRING LEN 30
END IMAGE
SUBROUTINE mySub
'Image usage
IMAGE Foo
'Ordinary variable declaration
localVal IS FLOAT
END SUBROUTINE
Keyword-delimited text blocks
TEXT TO myStringList
Here is the text I want to add to my StringList. See? There are no quote marks, I can even have quotes inside the text literal “like this" :)
I can even have multiple lines and {myValue} substitution.
END TEXT
TEXT TO myStringList
«Here is the text I want to add to my StringList. See? There are no quote marks, I can even have quotes inside the text literal “like this" :)
I can even have multiple lines and {myValue} substitution. »
END TEXT
Value-insertion within special text literals
specialtext_lit := '«' all_printing_ascii* '{'|
'}' all_printing_ascii* '{' |
'}' all_printing_ascii* '»' |
'«' all_printing_ascii* '»';
Variable function call syntax
Implementing the solution

Also interesting to read